Cloud SQL+Datastream+BQで分析基盤環境を構築
こんにちは!今年ももうすぐ終わりですね。今回はGoogle Cloud でデータ分析基盤を作成していきます。
(*下記で使用する用語について BQ = Big Query です。)
今回の環境
Cloud SQL に持っているデータをDatastream を通して、Big Query に保存するというのが今回の環境になります。
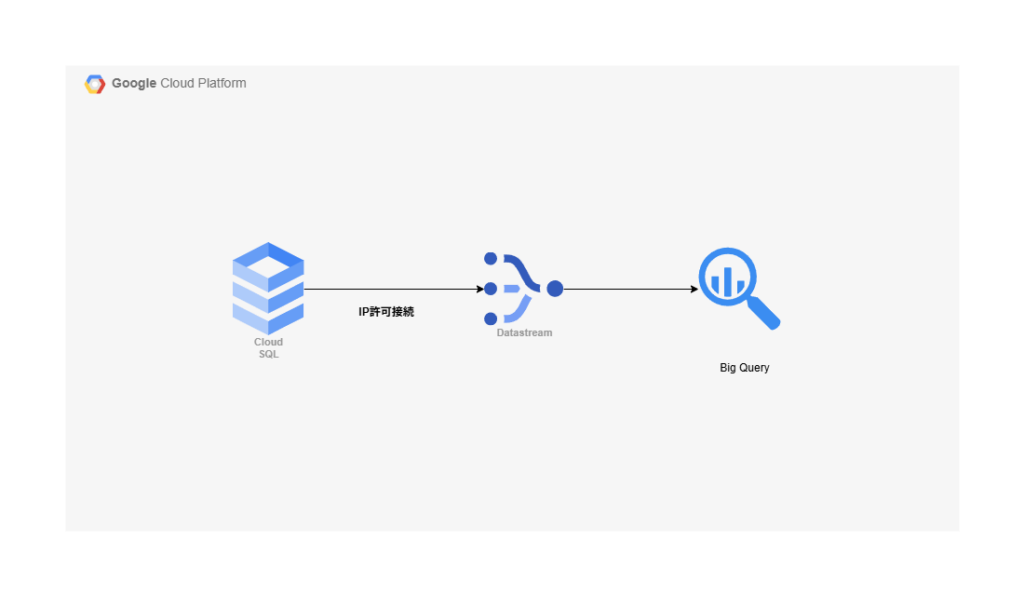
この構成について
Big Query はデータを分析するサービスであることと、Cloud SQL はデータベースであるので、そこに疑いの余地は少ないかもしれません。なんでGoogle Cloud なのですか?Big Query ではなくてもという質問などもあるかもしれませんが、Datastream ってどんな用途で使うんだっけと思うかもしれません。
今はDatastream が出てきたので、使うことはないかもしれませんが、Datastream が出てくる前は、Cloud Functions などを使用してデータの同期を行う方法があったようです。Cloud Scheduler + Cloud Functions で同期間隔を調整して、イベントドリブンで同期する方法ですね。
これでは、Datastream からBig Queryにデータを転送するときのMerge のような機能ができるのかが少し疑問ですね。Delete フラグなどをたてようと思うと、更に別の処理が必要になりそうだったり。。。後は、コンピューティングですので、どうしても遅くなったりとかの問題が発生しそうです。
Datastream が出てきてからは、Delete もUpdate 処理も検知されて自動でやってくれます。まあ、Binary log を追いかけているので、当然といっちゃ当然ですが、大分運用が楽になりそうですね。
後は、リアルタイムであったり、サーバレスのサービスなので、メンテナンスコストも低かったりということも考えるとDatastream を使わない手はないですね。。
発生する費用について
公式などを確認して調べた内容での課金形態です。不足分ありましたら、各自でご確認ください。
Cloud SQL 費用
端的にまとめると、スペックとストレージによって、課金が発生します。SQL Server はその限りではないので、ご注意ください。Microsoft のライセンス費用がかかりますね。後は、ネットワークレベルでも費用が発生しますが、かなりアプリケーションなどに依存する部分ですね。
(Enterprise か Enterprise Plus を使用するかによって費用が変わる場合があります)
スペックによっては変更されるので、Cloud SQL の費用については公式よりご確認ください!
https://cloud.google.com/sql/pricing?hl=ja#sql-server-pricing
Datastream 費用
端的にまとめると、データ転送量で課金が発生します。
課金:
-
転送するデータ量で課金 (GBあたりの課金)
(データ量が増えるほど単価は安くなる)- $2.568/GB
-
バックフィル:500GB までは無料
- 500GB を超える場合は、$0.514
Big Query 費用
端的にまとめると、分析料金とストレージ容量で課金が発生します。
課金:
-
クエリ(毎月1TiBまでは無料)
-
1TiB を超えると、1TiBごとに$6.25
-
キャッシュされた結果から取得したものは料金は発生しない
-
-
ストレージ料金 (10GiB までは無料)
- 10GB を超えた1GB/h あたり、$0.000031507 (アクティブ論理ストレージ)
ストレージによって、料金が変わるので要確認です。基本的にはテーブルに格納されているデータ量に基づいての課金になるとのことです。
https://cloud.google.com/bigquery/pricing?hl=ja
実際に構築してみる
Cloud SQL 自体はもう既に作成しており、データも何でもいいので、入っていることを前提にして今回の記事を書いていきます。
Datastream 接続部分
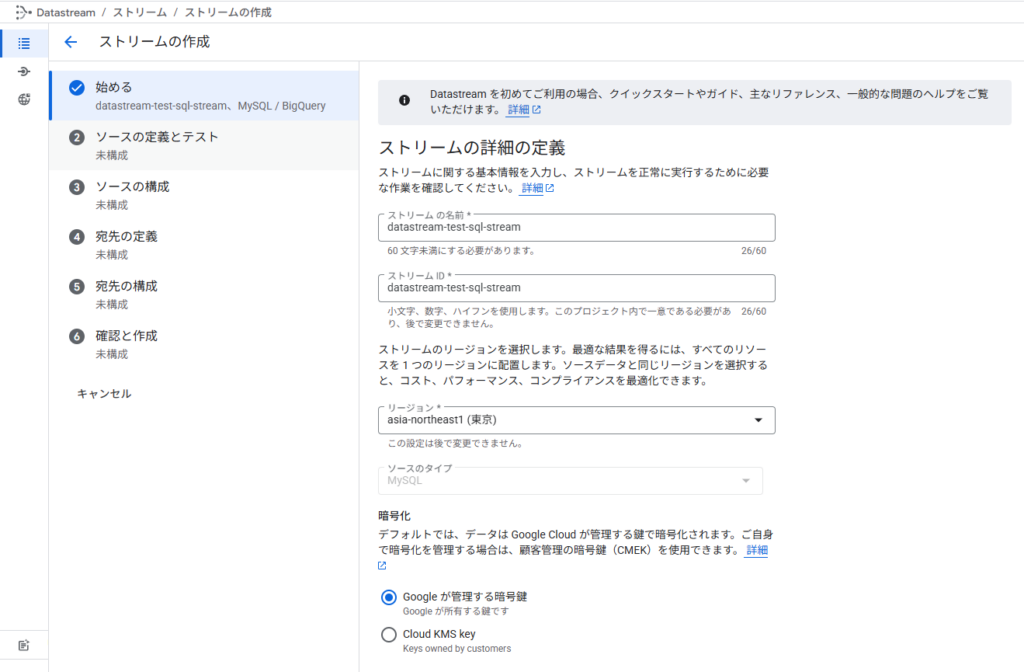
ストリームの名称などを決定
Cloud SQL と接続するストリームの名称やデータのソースタイプを設定していきます。今回はMySQL を使用しているので、MySQLがソースタイプです。
接続ユーザなどの定義
接続するためのユーザなどを定義していきます。今回はPassword は手動で入力することにします。本来はSecret manager を使うべきです。
接続設定の定義
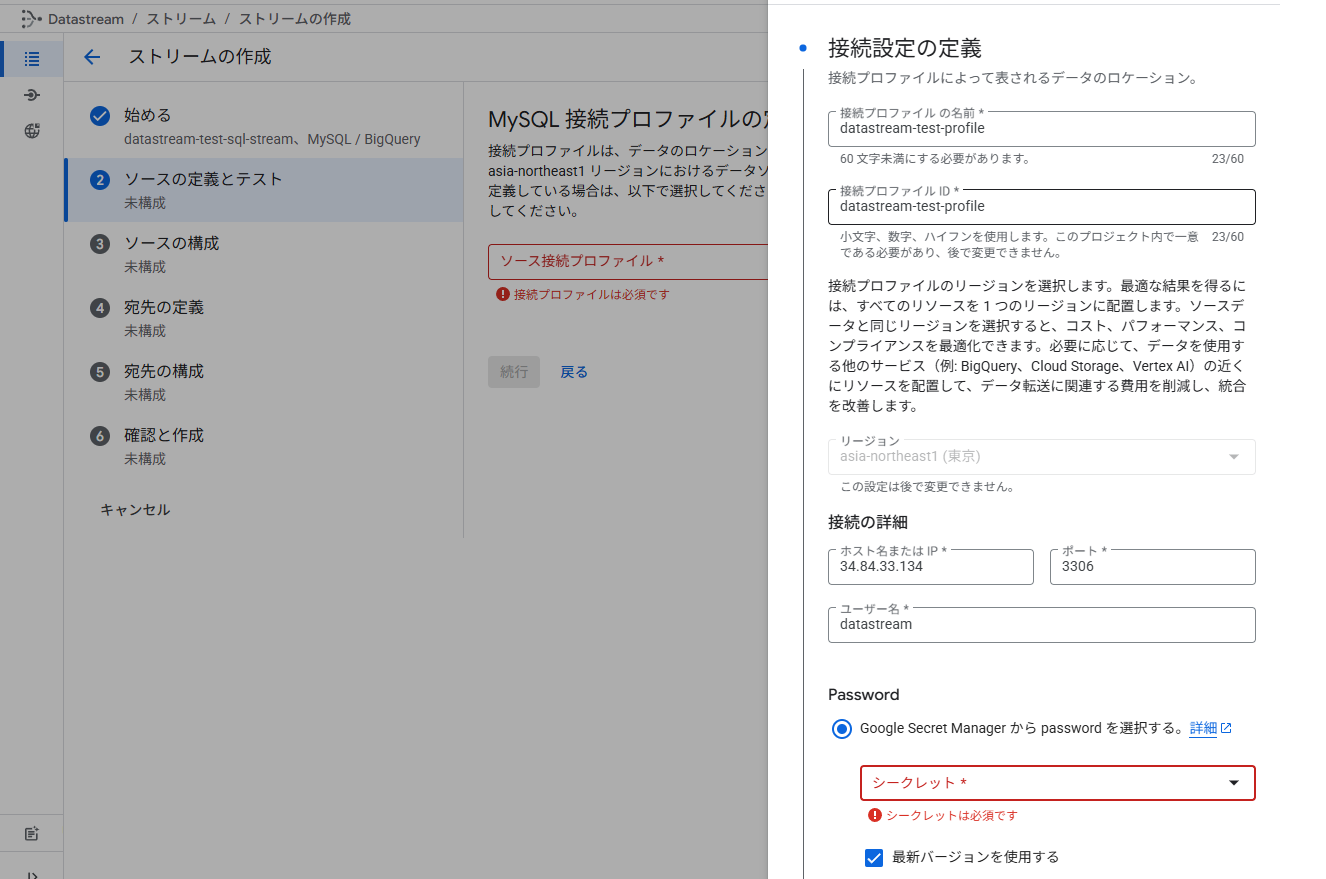
接続方法の定義
プライベート接続やSSH 接続などがあります。今回はIP 許可をして、接続していきます。

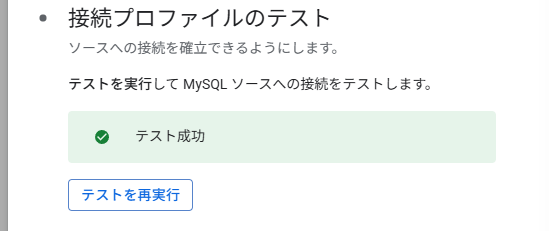
接続テスト
テスト成功と表示されたらオッケーです。
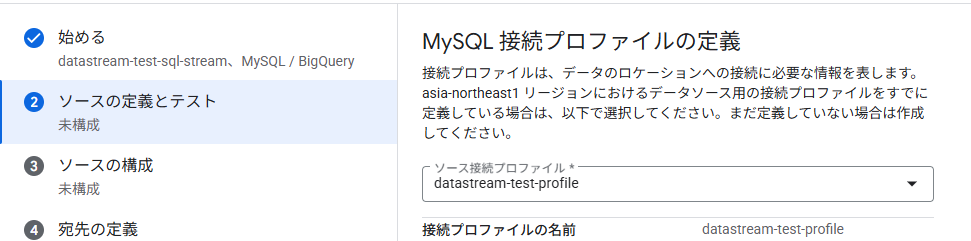
接続プロファイル完成
接続プロファイル自体は新規で作成が可能なので、他のデータベースからデータを取得する必要がある場合は、新しくプロファイルを作成してください。
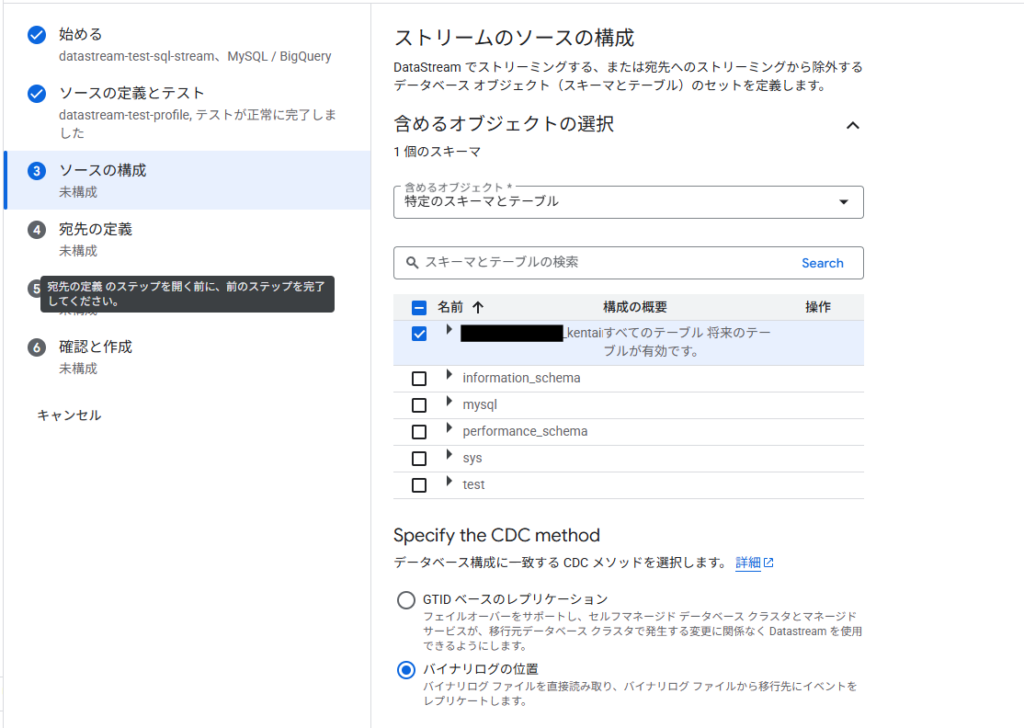
ソースの構成
ここでは、具体的にどのデータを転送するかなどを指定していきます。
今回対象にするテーブル選択
バイナリログでデータを追えるようにします。GTID はGlobal Transaction Identitfier というそうです。レプリケーションを張っているデータベースなどはこのGTIDを元にレプリケーションを追いかけるかどうかを判定するようになっています。今回は特段レプリケーションなどは関連しないので、素直にBinary log で追いかけます。
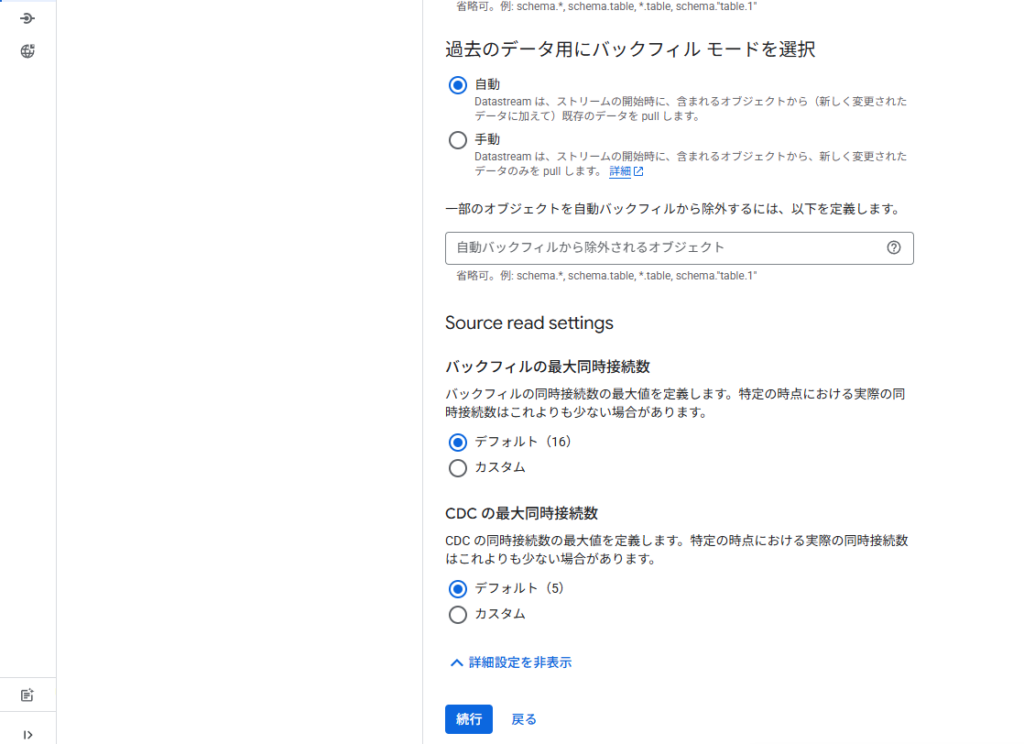
その他設定の定義
バックフィルなどや同時接続数などの定義をしていきます。同時接続数によって、スピードなども変わると思いますので、この辺は運用で調整していく必要がありそうですね。
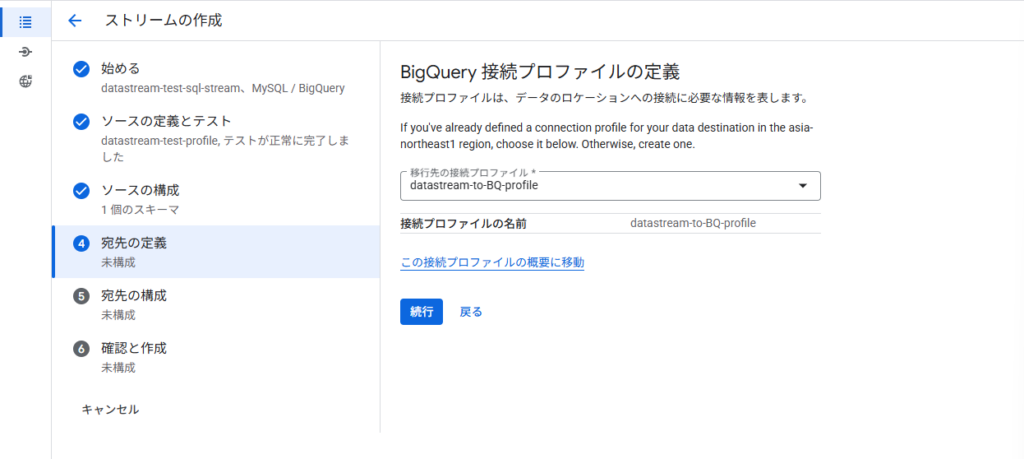
BQ と Datastream プロファイル設定
Datastream とBQ の接続のためのプロファイルを作成してあげます。ここでは名称しか設定していないので、現段階では知っておくべき設定などはないです。
BQにデータをストリーミング
ここはビジネス要件として大事になってくる設定項目かもしれません。スキーマとは
スキーマ設定とリージョン

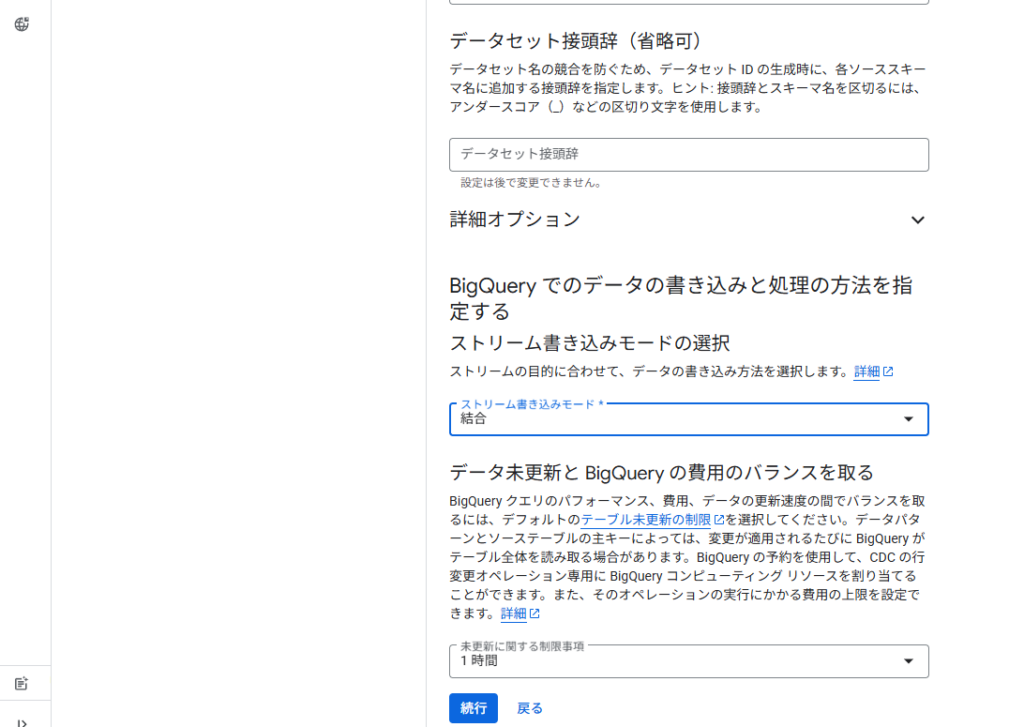
データの書き込み方法と頻度について
ここもどういうデータを扱っているかにもよるかもしれません。追加のみにすると既存データは履歴として残ります。ただし、行の物理削除が行われないみたいなので、論理的には削除されているのだとおもいます。「結合」が一般的なデータではベストではと思ったりしてます。
CDC からBig Query にデータ送信
再開ボタンを押すとCloud SQL からCDC を通して、データがBQ の方に転送されます。
まとめ
Datastream があることによって、大分データの同期が楽になったりしそうですね。このブログを書いているときにNotebooklm でもデータ分析ができるという記事を読んでなんだと?って思いましたが、この基盤が揺らぐことは当分ない気がしますので、まだまだBig Query ですね!
検証するときは、ほっとくとCloud SQL で費用が発生するのでちゃんと停止するか削除をお忘れなくお願いします!
クラスメソッドさんマジで書くのはやい。。。
https://dev.classmethod.jp/articles/notebooklm-datatables-sample