
こんにちは!前回にデータ分析基盤を作成する記事を作成しました。ただ、データ基盤を作成する上でなんか色々用語ありますよね?データレイク(Data Lake) とデータウェアハウス(DWH) です。
これって何が違うんでしょうか?今回はこれをGoogle Cloud のサービスを使いながら整理できればなと思います!前回書いた記事もぜひ見てみてください!
まずは、データレイクから解説していきましょう!

データレイクとは?
データレイクは、色んな種類のデータが入っている池です。生データが格納されています。なので、データの形式を問わず保管されています。ただ、整理されていないという意味ではないので、その点ご注意ください。
大元のデータってどんなだっけっていうのをたどるのにつかわれたりしそうですね。この池を見れば怪しい時はたどりましょうということです。
さて、色んな種類のデータとはどんなものがあるのでしょうか?
構造化データ
RDBMS やCSV などの構造になっているデータです。下記のようにカラムなどがしっかりTable 形式で定義されている行列のようなデータのことです。
| id | name | age |
| 1 | Tom | 10 |
| 2 | Kim | 11 |
半構造化データ
XML やJson などがそれにあたるらしいです。構造化データまではしっかり整ってないけど、それなりにKey Value 型としても取得できますね。下のような形のデータです
{
"id": 101,
"名前": "田中 太郎",
"年齢": 25,
"プログラミング言語": ["Python", "JavaScript", "Go"],
"住所": {
"郵便番号": "100-0001",
"市区町村": "東京都千代田区"
},
"プレミアム会員": true
}非構造化データ
画像ファイルや音声などのデータです。内部を見れば構造化されているのかもしれませんが、meta データとかデータ自体が構造になっていないですよね。これが非構造化データです。
このようなデータが一つの池の中に入っているイメージなのが、データレイクです。
次にデータウェアハウスとはなんでしょうか?
データウェアハウス (DWH) とは?
データウェアハウスは構造化されたデータが格納されています。MySQL などのデータベースとの違いとしては、データベースは分析用としての用途ではないです。もう既に分析できるデータの状態が出来ています。
分析できる状態ということは加工がすでに完了しているということですね。どういう風に加工していくのでしょうか?ETLという方法があるそうです。
Extract (抽出)
Transform (変更・加工)
Load (書き出し)
ETL 構成
Cloud storage が Extract の部分です。 Transform がCloud Data Fusion です。最後にLoad の箇所が、Big Query です。Cloud storage にためてあるデータ(Data Lake) をData Fusion で加工して使う方法になります。
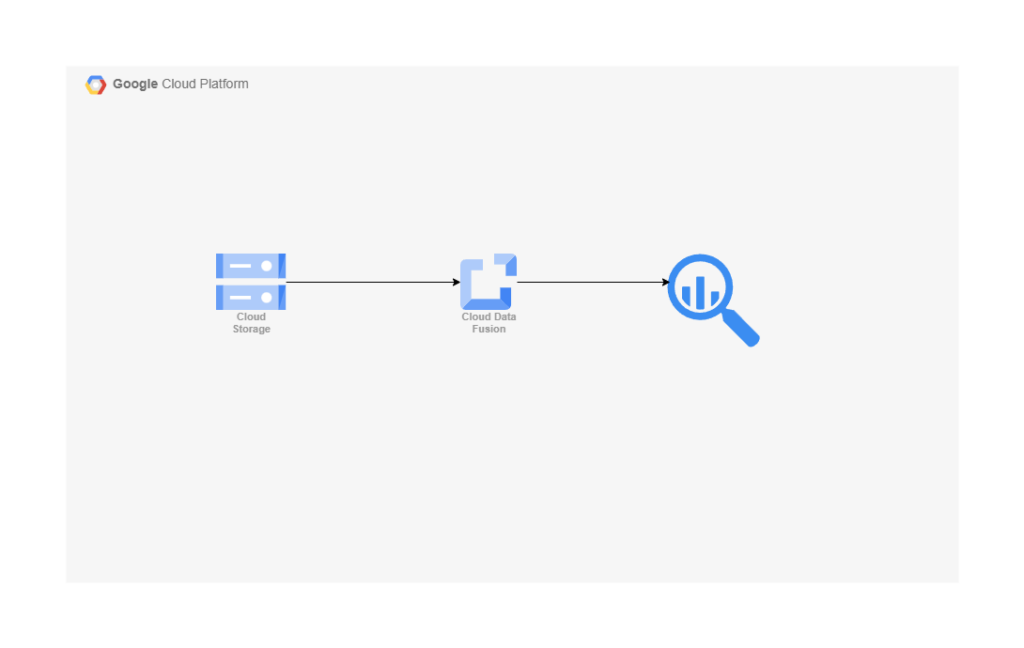
DWH を実際にデータを使うことではこの記事では実施しないので、実際の動作が気になる方はぜひ触ってみてください!
番外編
でも、DWH って分析基盤としては優秀なのですが、複数の部門が使用した場合、データが競合してしまったりということが発生するようです。みんなが同じようなデータを見て分析するのでは、確かにリソースは競合しますね。。。
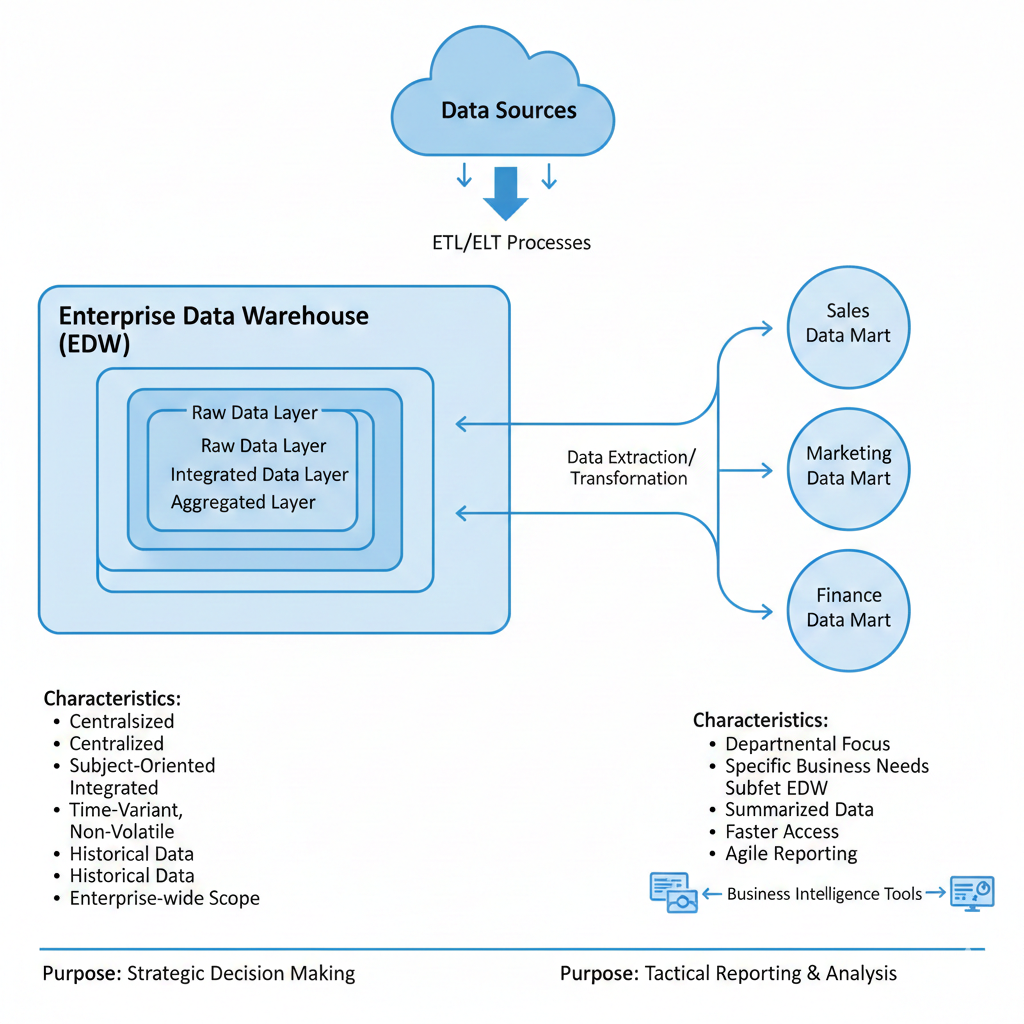
そんな時にデータマートという概念があるそうです。データマートとデータウェアハウス何が違うんだというところですが、データマートは役割が分けられているが、データウェアハウスは倉庫なので全てのデータが一個の倉庫に入っています。
データマートを作ることによって、これは経理部とか営業部が使うデータみたいな感じで用途が分けれるようになっています。下の画像はGemini に作成してもらいました。下記の図のようにSales(営業)とMarketing とFinance (経理とか?)のデータなどの用途に分けることによって、被ることなく分析ができるようなイメージです。
まとめ
今回は技術的なところというかは、概念的なところの説明に近かったかなと思います。データレイクとはなんぞやであったり、データウェアハウスとの違いは何だっけというところに焦点を当てて解説しました。
データ関連はこれから勉強していくので、より内容のある役に立つ記事を目指して頑張ります。ではでは。
参考サイト

\ 最新情報をチェック /


コメント